


















































































These Pixar and Apple alums want to change the way you create generative AI video

Intangible is the first tool that could make generative AI video truly usable. The new web app—created by Pixar, Apple, Google, and Unity alumni—is trying to change the user experience of generative AI video by letting you fully control your video using a 3D interface, thus solving the lack of control of current text prompts.
Think about it as a 3D animation program that lets you control the stage, characters, and camera in your film, with a generative AI rendering engine that will turn those elements into reality. Intangible’s current version feels half-baked, and it will not produce The Godfather yet, but it’s definitely a step in the right direction for the generative AI video user experience.
“To deliver professional-grade results in creative industries like film, advertising, events, and games, the directors, producers, and every creative on the team needs control over set design, shot composition, art direction, pacing, cameras, and more to deliver on the creative vision,” Intangible chief product officer Charles Migos tells me over email. “Current AI models are reliant on extensive prompting, and language alone isn’t enough to convey creative intent. By providing generative AI models with spatial intelligence, Intangible allows creatives to get closer to professional-grade results with less prompting, more feel, and more control.”
Migos is right that we need a better way to control the imagination of generative AI video engines. While generative AI video is getting to the point at which it is truly indistinguishable from reality, creating it is like rolling the dice. There’s still a chasm between the vision in your mind and what comes out of Google’s Veo 3 or Kling. This makes it pretty much unusable for everything but memes, skits, storyboards, and the occasional ad stunt.
While some AI models let you set camera paths or define some characters and objects using images, the prompts that “create” the videos are inherently limited by the interpretable nature of language. Every person and AI visualizes any given text differently. That’s the beauty of reading a book, but it’s a limitation when it comes to creating what you have in mind. That’s why Alfred Hitchcock meticulously planned his films using storyboards, so that everyone in the production could truly visualize the “intangible” nature of his imagination to faithfully capture Cary Grant’s desperation as a biplane tried to kill him in North by Northwest.
Spatial intelligence
Migos and CEO Bharat Vasan believe that to truly unleash the power of generative AI for video production, we must add “spatial intelligence” to the interface. Computer vision expert Fei-Fei Li, known as the godmother of artificial intelligence, has defined spatial intelligence as the ability, both in humans and artificial intelligence systems, to perceive, interpret, reason about, and interact with the three-dimensional world. This involves not just recognizing objects, but understanding their positions, relationships, and functions within a physical space, and being able to act upon that understanding.
“By building in interactive 3D from the outset, Intangible’s world model gives generative AI image and video generation models the ability to be more precise, without extensive prompting,” Vasan says. This precision is what current text-to-video tools fundamentally lack. When you describe a scene in words, you’re forcing the AI to interpret spatial relationships through language—an inherently imprecise translation that often results in the AI changing things and adding objects or actions that you didn’t have in mind.
Intangible grounds generative AI models in structured 3D scenes with real camera control and spatial logic, which Vasan says “provides best-in-class coherence in the results, which we further improve with object descriptions, reference imagery, and fine-tuning models [LoRAs, or low-rank adaptations]. The goal is to address one of the biggest complaints about current AI video tools: the lack of coherence and continuity between frames.”
How it works
The platform allows users to build custom 3D scenes using drag-and-drop objects, set up cameras, and control them. The interface is pretty simple: You can start from a preset scene or with a blank world. There’s a general viewport that shows you the scene, with a ground ready for you to start dropping buildings, characters, and other objects from a library of more than 5,000 assets.
At the bottom of the interface, a toolbox gives you access to all you need. To the left, icons allow you to open a scene panel in which you can add and reorder all the shots that will form your final video. In the center, a central prompt allows you to add new objects using text. To its left, there are three icons to add objects to the scene. The first one allows you to display a palette to pick an object from the library of premade assets. Then there is an icon to add primitives—like spheres, cubes, or pyramids—to create your own basic objects. Finally, a third button lets you add what the company calls “interactables”: cameras, characters, waypoints to tell the camera where to move, and “populators,” which will fill your scene with variations of the same objects, like bushes or shrubs in a forest.
Working in this interface is pretty straightforward. Objects in the scene can be moved around with standard 3D handles, with arrows to move, cubes to scale, and arches to rotate the objects in all three axes. The interface—at least using Chrome in my Macbook Air 15 with M2 chip—was sluggish but usable, with some serious pauses at the beginning of the session, which got better later on.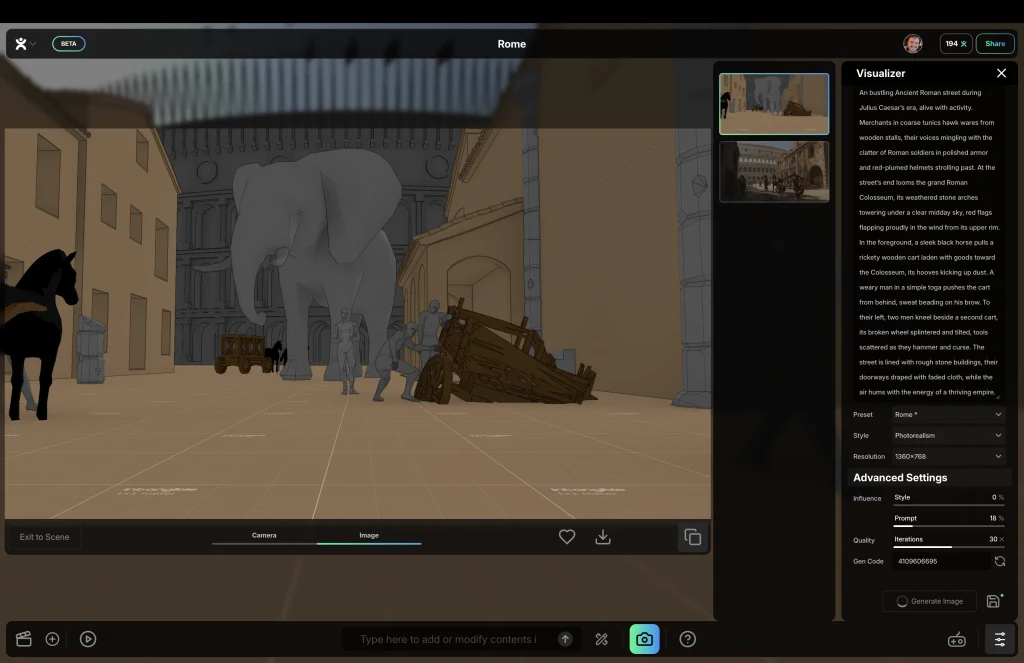
To the right of the prompt field, there are two icons that switch between edit and visualization modes. The latter opens a side panel on the right of the screen that contains all you need to tell the generative AI how to render your scene: how the objects look, how they interact with each other, what the lighting and the atmosphere look like, and anything else you want to define. There are also options to set up the time of the day or the final look of your video, which includes modes like photorealism, 3D cartoon, or film noir. Once you write your prompt, click the “generate” button . . . and that’s it.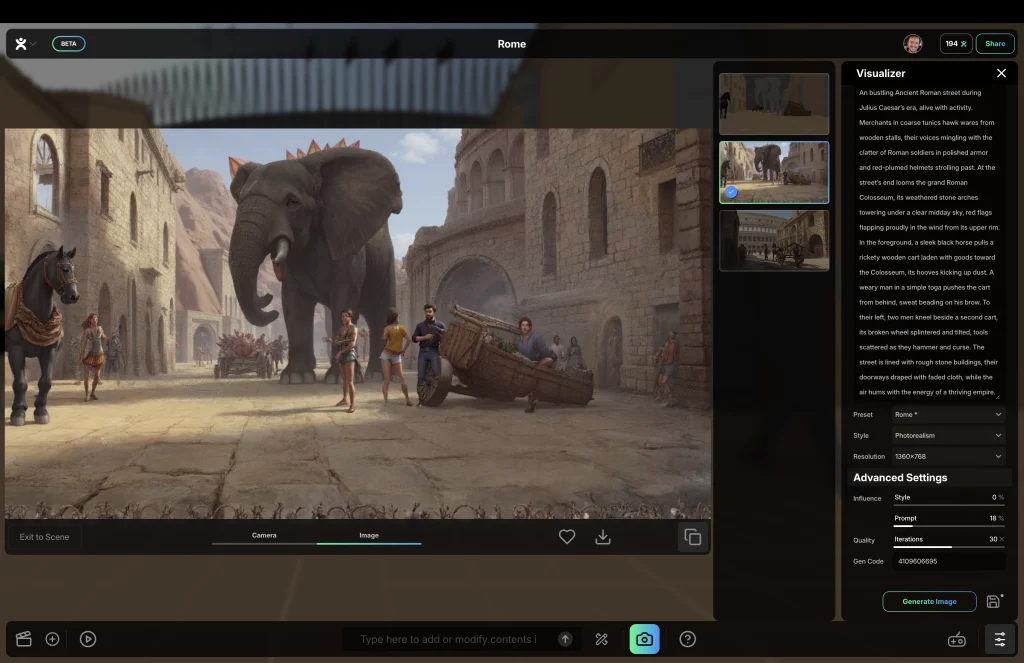
The idea is good. I tried it (here, it’s free for now), and it works-ish. I started from one of the templates, a Roman urban scene. I quickly added an elephant, positioned and scaled it up with the object handles, and then I clicked on the visualization icon to set the prompt (a premade one was already there), and clicked on “generate.”
The results were just okay. Intangible does what the company claims, but it still makes mistakes. You can see it in the way it rendered this scene with a giant elephant in a Roman street. The Colosseum is gone, replaced by a mountain and some pointy things I can’t identify. There are rendering mistakes as well, and the people are wearing the wrong clothes—that is, unless I missed the history class in which they teach that Romans wore jeans and Daisy Dukes.
Once you have your shot, you can turn it into a video. This is where things get disappointing. I thought Intangible would use its own generative AI engine to directly interpret the 3D scene itself—as Nvidia demonstrated six years ago—and turn it into a final photorealistic video using the objects to guide the final rendering. In reality, it feeds your still image to the latest version of Kling—a popular, pretty realistic rendering engine from China that can turn any image into a living video, following a prompt. If you are a 3D artist, you will be better off combining your current workflow using Kling or any other image-to-video generative AI (as some people are already doing).
If you are starting from scratch with 3D software, Intangible can work for you even if it is nowhere near perfect. The software will get better: “In the next three years, we expect tools like Intangible will be able to cover all aspects of preproduction and digital production for existing forms of media,” Migos and Vasan tell me. They also believe that “AI tools bring an opportunity to expand visual storytelling as an art form, creating new categories that human creativity thrives in, as linear, interactive, and immersive media blend. . . . We expect tools like Intangible to be both simple and powerful enough that it empowers a new generation of creatives, not just those who are technical or prompting experts.”
For now, despite the glitches, Intangible’s premise is the right one: People need a better way to control AI video because text is not a good interface when you are trying to visualize an idea. Spatial intelligence may be the key to solving it. At the very least, this new software shows that, when it comes to artificial intelligence, we still need to work on a better, more natural, and precise user experience.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










